Data Science Product Owner
Intro
With the increasing number of Data Science and AI based products, we need to think more the work organization within Data teams.
Inspired by Agile Frameworks and DevOps approaches, new Data and Machine Learning development workflows are being implemented (DataOps, MLOps…). While Agile methodologies have proven their efficiency in software development organizations, some adaptations are needed in Data Science and ML areas.
We will discuss in this article one of these adaptations: Role and skill set of the Product Owner.
The first section describes quickly the main principles related to Agile methodology in traditional software development.
The second section presents specificities of Data and ML solutions.
In the last section, I try to discuss the new tasks and responsibilities of Data Science Product Owner.
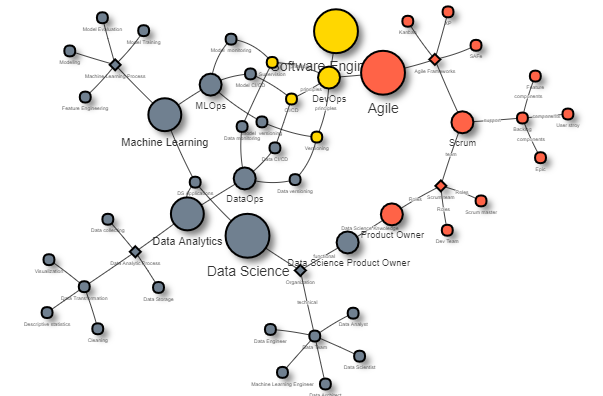
The following interactive graph draws the connection of different concepts used for this article.
library('visNetwork')
DSPO.links <- read.csv("data/DSPO.links.csv", header=T, as.is=T, sep = ";")
DSPO.nodes <- read.csv("data/DSPO.nodes.csv", header=T, as.is=T, sep = ";")
vis.DSPO.nodes <- DSPO.nodes
vis.DSPO.links <- DSPO.links
vis.DSPO.nodes$shape <- vis.DSPO.nodes$shape
vis.DSPO.nodes$shadow <- TRUE # Nodes will drop shadow
vis.DSPO.nodes$title <- vis.DSPO.nodes$concepts # Text on click
vis.DSPO.nodes$label <- vis.DSPO.nodes$concepts # Node label
vis.DSPO.nodes$size <- vis.DSPO.nodes$concept.size # Node size
vis.DSPO.nodes$borderWidth <- 2 # Node border width
vis.DSPO.nodes$color.background <- c("slategrey", "tomato", "gold")[vis.DSPO.nodes$concept.type]
vis.DSPO.nodes$color.border <- "black"
vis.DSPO.nodes$color.highlight.background <- "orange"
vis.DSPO.nodes$color.highlight.border <- "darkred"
vis.DSPO.nodes$font.size <- vis.DSPO.nodes$font.size
vis.DSPO.links$title <- vis.DSPO.links$type # Link title
vis.DSPO.links$label <- vis.DSPO.links$type # Link label
vis.DSPO.links$width <- vis.DSPO.links$width # link width
vis.DSPO.links$length <- vis.DSPO.links$length # Link length
visNetwork(vis.DSPO.nodes, vis.DSPO.links, height = "500px", width = "100%") %>%
visOptions(highlightNearest = list(enabled = T, degree = 2, hover = T)) %>%
visOptions(selectedBy = "concept.category") %>%
visLayout(randomSeed = 123) Agile approaches in Software Development
Agile approaches
History
Agile approaches consist of a set of practices and values for driving and building complex IT products. They were designed in reaction to the rigidity of traditional approaches in software development (V-cycle, waterfall…).
They are based on an iterative, incremental and adaptive development cycle. The four fundamental values defined in the Agile manifesto are:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
See the Agile manifesto to know more about Agile values.
Frameworks
There are various methodologies that offer IT product development frameworks based on the principles set out in the Agile Manifesto: Extreme Programming (XP), Scrum, Kanban, SAFe …We will focus on the Scrum framework for the rest of the article as it is the most adopted one.
Roles
Scrum defines 3 roles:
- The Product Owner who carries the vision of the product to be achieved and considered as the representative of the customer.
- The Scrum Master is the responsible for the application of the Scrum method
- The development team that makes the product
Work Organization
- Sprint: It is a relatively short period of time (2 to 4 weeks), during which the development team realizes and tests a set of features defined with the Product Owner.
- Product Backlog: It is an ordered and prioritized list of features constituting the IT product.
- Items: The Product Backlog is composed of different “items” which contain a detailed description of the components to be carried out: requirements, improvements and corrections to be made, tests, definition of “Done”… Those items are often grouped into different categories to better manage the product backlog: User stories, epics, features, tasks, bugs … A list of items is selected by the team every sprint. This list constitutes the “Sprint Backlog”.
- Sprint planning: A Scrum event during which the development team selects with the Product Owner the prioritized items that it considers to be able to achieve during the sprint.
- Sprint Review : A Scrum event that serves the development team to present the achieved features during the last sprint in order to collect feedback from the Product Owner and end users.
- Sprint Retrospective: A Scrum event designed for inspecting the past sprint and identifying potential improvements in terms of productivity, efficiency, working conditions…
- Daily meeting: A 15-minute daily standing meeting for synchronizing the daily tasks of the development team.
You can find out a complete description of Scrum methodology here.
Work organization tools
There are several management and planning tools for product development based on Agile methodologies. These tools offer different festures such as sprint reports, dashboards, definition of the roadmap, velocity monitoring … Among these tools we can mention: Jira, Trello, Asana, confluence, Kanboard, OpenProject, Gitlab, GithubProjects, OpenProject …
DevOps
DevOps is a set of practices that combines software development (Dev) and IT Operations (Ops). With respect to Agile approaches, it encourages more collaboration and process sharing. These practices are essentially based on shorter release cycles with an increase in the frequency of deployments and continuous deliveries.
Continious Integration/Continious Deployement (CI/CD):
- Continuous Integration: Frequently integrate and merge code changes into the main code branch by setting up automated tests that run whenever new code is validated.
- Continuous Deployment: Respect frequent and automated deployment of new application versions in a production environment. (Tools: Jenkins, CicleCI, Gitlab…)
Version management: Manage different versions of code by tracking revisions and change history to facilitate code review and retrieval. (Tools: Git, Github, Apache Subversion, bitbucket…)
Continuous monitoring: Set up continuous monitoring and alerting tools to have complete real-time visibility of the applications/infrastructure performance and integrity. (Tools: ELK, Sensu, Zabbix, Nagios, Amazon CloudWatch…)
The Product Owner
The Product Owner plays an important role in an Agile organization. We can categorize his tasks and responsibilities into 5 main families:
Client / team interface: The PO is the representative of the customer and the product users in the Agile team. He/She transforms customer needs into technical features and guarantees that the product meets their expectations. He/She sets up metrics and KPIs to assess product usage and users’ behavior in order to identify potential improvements.
Product Development management: The PO is the master of the Backlog and the referent of product roadmap. He/She is in charge of:
- Proposing functional specifications and ensuring the correct translation in terms of technical specifications
- Writing User Stories and defining their acceptance criteria
- Defining acceptance protocols and criterias
- Validating achievements using functional tests
- Guarantee of delivered features’ quality
- Feeding the roadmap with prioritized features.
Collaboration: By nature, the PO must collaborate with different members of the development team. As a product referent, he/she also needs to coordinate with other teams and departments: sales, marketing, infrastructure, etc.
Communication: The PO must share the product vision inside and outside the company. He/she can organize Product Discovery workshops with the team and clients. He/She is also responsible for the quality and completeness of the documentation.
Technology watch: The PO must ensure a continuous watch on the market in order to be able to situate the product among the competition.
Agile aproaches * Data Science products
In the intersection of statistics and computer science, Data Science applications are fast growing. While at the beginning, the majority of data science work stopped at the level of exploration and prototyping, increasing performance of technical tools, scientific efforts and use cases maturity have enabled the shift to industrialized and operational Data and ML products.
These evolutions need to be accompanied by methodological tools for the management of a Data product and then rethink the application of agile approaches as well as the role of the Product Owner in Data Science workflow.
Data Science produtcs
We can categorize Data Science products into two main families: Data Analytics & Machine Learning.
Data Analytics: They essentially consist of a data processing pipelines attempting to extract knowledge and insights of the studied phenomena by using collected raw data:
- Data Extraction: Frequency, disponibility, schemas, formats, data models…
- Data Storage: Data warehousing, datalake, relational Databases, NoSql Databases, Cloud Storage platforms….
- Data Exploration: Profiling, Descriptive statistics, visualization…
- Data Transformation: Cleaning, aggregating, automatic reporting…
Machine Learning: It refers to products that are based on learning models (supervised, unsupervised, self-supervised) and generate services aiming at replacing human tasks. We can distinguish 5 families of ML solutions on the market: recommendation and scoring systems (e.g. movie recommendation), prediction of actions or events (e.g. prediction of clicks on a video), classification (e.g. classification of emails as spam / not spam), generative models (e.g. translation), and clustering (e.g. clients segmentation).
In addition to the data analytics pipelines, ML products integrate specific techniques:
- Data transformation: division into test/train, feature engineering, data augmentation…
- Modeling: testing different statistical models, model design, hyperparameters tuning……
- Model training
- Model Evaluation and validation: cross validation, evaluation metrics…
- Model serving
- Model monitoring
DataOps & MLOps
DataOps and MLOps are relatively new disciplines that seek to systemize the entire Data Science workflows (data pipelines and ML lifecycles), from science to production. They refer to a set of practices and tools aiming at improving the collaboration between data science and DevOps teams in order to accelerate the time to market of data science applications.
| DataOps | MLOps | |
|---|---|---|
| CI/CD | It consists of implementing CI/CD methods for managing the developement and the orchestration of data pipelines. (Tools: Dataflow, Luigi, Airflow…) |
Continuous integration of testing/validating data. Continuous deployment of an entire ML training system and prediction services. Continuous Training by automatically retraining and serving models. (Tools: MLflow, kubeflow, Cortex…) |
| Version Management | The versioning of the different Data sets collected, stored, and manipulated by using data versioning systems and Data catalogs. (Tools: DVC) |
Versioning of ML pipelines and metadata (data version, modifications, parameters, stages..) (Tools: MLflow, kubeflow…) |
| Monitoring | Monitoring the collected and transformed data during the data pipeline cycle (quality, schemas, volumetry…) and implementing alerting systems for supervising specific indicators. | Model monitoring by tracking prediction performance metrics (accuracy, sensitivity…), input data quality, system latency… (Tools: MLflow, kubeflow, Amazon SageMaker…) |
You can find here a comprehensive documentation about MLOps principles and workflow.
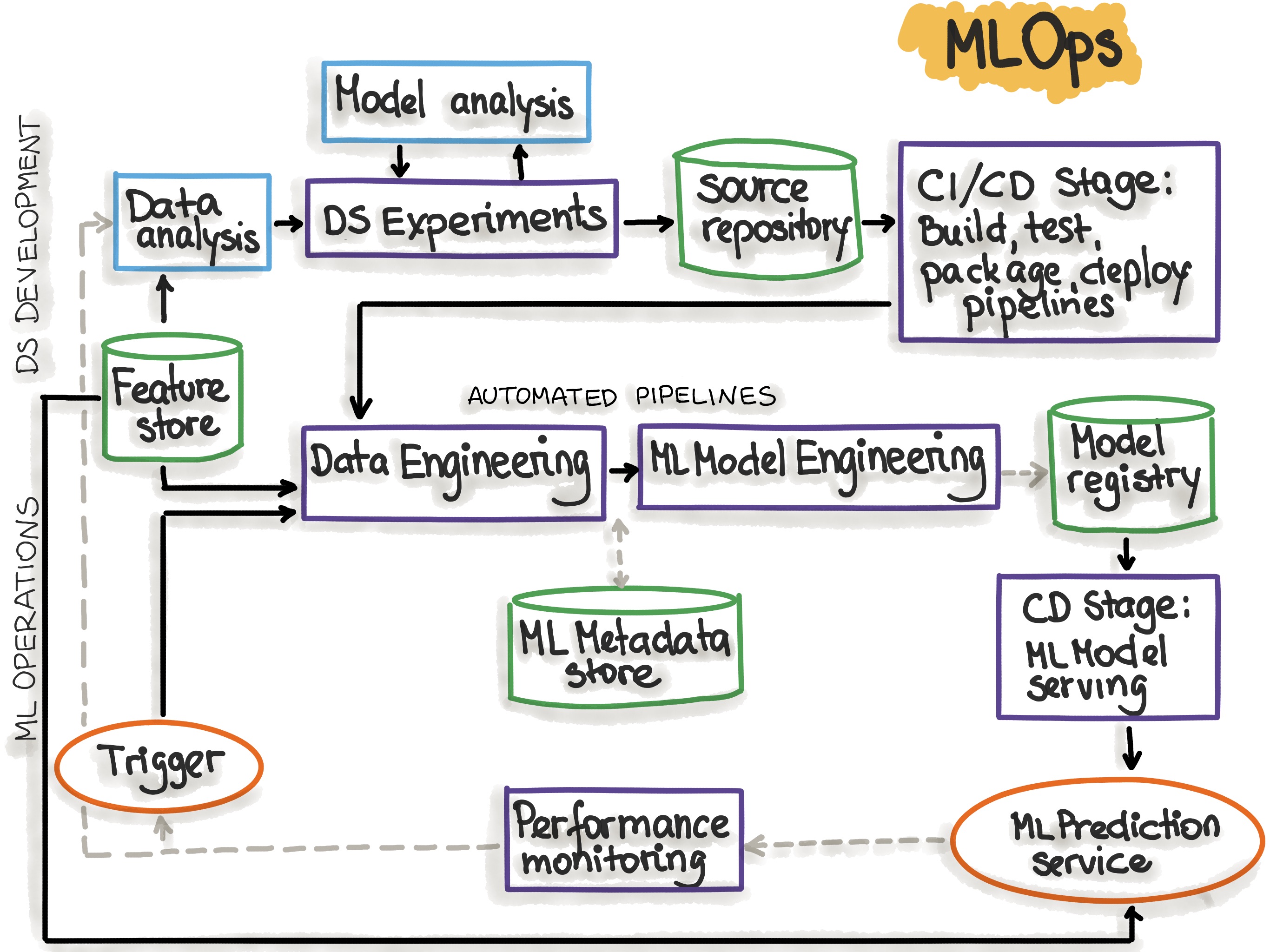
MLOps: Continuous delivery and automation pipelines in machine learning (source: “https://ml-ops.org/content/mlops-principles”)
The Data Science Product Owner
Due to the differences between traditional IT solutions and data-driven solutions, new skills are needed for accurately managing Data and ML/AI products. Specificities of Data Science products (in terms of mathematical foundation, exploratory dimension and data-driven workflow) are significantly impacting and reshaping product development lifecycle. Therefore, Product Owner role and knowledge may expand to include the following aspects:
Product Development management:
- Feasibility assessment: Streamlining the interface between R&D processes (feasibility assessment, exploration, literature review…) and production.
- Scientific approach: Integrating the necessary steps for implementing scientific approach in product development (observation, formulation of problems, hypothesis testing, phenomenon modelling, experimentation, evaluation…)
- Intermediate delivery: Designing intermediate delivery adapted to the experimental nature of data science workflows which do not necessarily result in a deployed feature.
- Complex estimation: Estimating efforts and charges for deploying a Data Science feature may be complex due to the exploratory phase and dependency to data availibility and quality. The PO needs hands-on experience to better estimate featuress value and complexity and integrate them to the development cycle.
- Data-driven: As a referent of a data-driven product, the PO must know very well the input data (quality, availability, formats, source, etc.). Manipulating the data helps for better anticipating constraints and potential improvements of the delivered solution.
- Modelling: The Data Science PO should master the Machine Learning pipeline (model designing, testing, training, validating,serving…) and be able to explain model weakness for guiding the product roadmap to the most effective improvements.
- Validation: The validation of data-driven features requires skills in data wrangling, use of notebooks to standardize tests, and a good understanding of evaluation metrics, etc.
Collaboration: In addition to the traditional development team, the Data Science PO must coordinate the tasks of various profiles making up the Data team: Data Analysts, Data Scientists, Data engineers, Data Architects… He/she should know their responsibilities, skills and constraints in order to better coordinate the development phases.
Technology watch: The development of industrialized applications based on data science and machine learning remains a fairly young profession. It is important for the data product team, and particularly the PO, to be up to date in terms of tools, techniques, methods, algorithms and technologies… This makes it possible to better anticipate the changes to be integrated in order to improve some performance.
I dedicate this article to my ex-colleagues in OpenfieldLive, together we tried to apply Scrum framework for developing Location Intelligence solutions, we tried to find our own methodology and collaboration degree between Data and DevOps teams, and with them I experimented the role of Data Science Product Owner.
Saif Shabou
Building data products for a better planet
My research interests include Artificial intelligence and data products designing and deployement.